
Anomaly detection in computer vision is a vital technique used to automatically identify irregular patterns or unexpected elements within images. From detecting manufacturing defects to spotting medical anomalies in scans, its applications are both broad and critical. This process is typically divided into two key categories: image-level anomaly detection, which assesses whether an entire image is normal or abnormal, and pixel-level anomaly detection, which pinpoints the exact location of anomalies within the image.
Each category involves unique approaches and deep learning models designed to handle the complexities of visual data. In this blog, we’ll break down both types of anomaly detection, explore the core methods used, and highlight how each contributes to building more intelligent and reliable computer vision systems.
Image Level Anomaly Detection:

The image-level anomaly detection can be further classified into 4 categories, which are
- Density estimation.
- One-class classification.
- Image reconstruction
- Self-supervised classification.
Density Estimation:
This method generates a probability distribution model of the normal images and sets it as a reference. The model then creates a new probability distribution for test images and determines whether the new image is normal or contains an anomaly. Such density estimation techniques are widely used in anomaly detection in computer vision to evaluate the likelihood of image abnormalities.
For calculating a probability density model, a large amount of training data is required, and image data typically has high feature complexity. This makes the problem quite challenging. To address this, researchers often prefer deep generative models over traditional density methods such as the Gaussian model (Bishop, 2006) or nearest neighbor (Khan, et al., 2009)
However, deep generative models like variational autoencoders (Kingma, et al., 2014) or flow models (Kingma, et al., 2018) still face limitations when applied to real-world anomaly detection in computer vision scenarios.
One Class Classification:
In this, a decision boundary is constructed to identify between the normal and abnormal images in the feature space. Classical methods include one-class support vector machines (Sch¨olkopf, et al., 2001). These methods do not require a large number of training data because they do not have to find a definite value for the probability distribution model. Recently, researchers have been working on combining both convolutional neural networks with support vector machines to develop a hybrid model.
Image reconstruction:
The benefit of using the image reconstruction approach in anomaly detection in computer vision is that it maps the image to the latent space, which is the low-dimensional vector in feature space. The intuition behind reconstruction is that the error in reconstruction is small when a normal image is reconstructed, and the error is large when there is an anomaly present in the image. Autoencoders have been comprehensively used for image reconstruction in anomaly detection in computer vision.
Autoencoders have the smallest middle layer, which compresses the features of the given image. (Japkowicz, et al., 1995) was one of the first people who used autoencoders for anomaly detection in computer vision. The working principle of his model was that the extra information of a normal image is not necessarily extra in an abnormal image. Generative adversarial networks have also been used for anomaly detection in computer vision using reconstruction.
The adversarial network is first trained on normal images and then the difference between the normal and abnormal images is calculated to determine the presence of an anomaly. The only drawback is that the model needs to perform an iterative search process which makes the model inefficient for real-world applications.
Self-Supervised Learning:
The reason behind using self-supervised learning is that the models can learn important features and parameters from the given image on their own. They can extract low-level features and high-level features. (Golan, et al., 2018)in his work developed a neural network called RotateNet whose purpose was to find if the given image has been rotated or not.
His model was able to learn both the low and high-level features because to distinguish between the normal and abnormal images the model had to learn the position, direction, and shape of the object in an image. The only limitation of RotateNet was when it had to deal with symmetrical objects.
Pixel level anomaly detection:
Pixel level anomaly detection can be further divided into two main categories. One is the image reconstruction, and the other is feature modeling.
Image reconstruction:
The assumption behind using image reconstruction at the pixel level in anomaly detection in computer vision is that since the model is trained on normal images, it cannot reconstruct abnormal images with accuracy. As a result, we observe a large reconstruction error when reconstructing abnormal images. The evaluation is done by comparing the pixel differences between the reconstructed image and the normal image.
L1 and L2 distance calculation methods are used to detect abnormalities at the pixel level. Baur combined both variational autoencoder and generative adversarial networks to find abnormal lesions present in the images taken by a magnetic resonance imaging machine (Baur, et al., 2018).
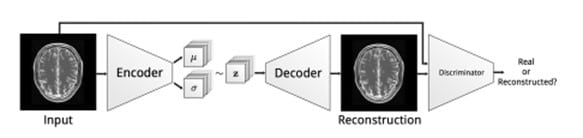
Source Baur, et al., 2018
Feature Modeling:
In this approach, the anomalies are not detected in image space but rather in feature space. The development of the feature space of normal images can be achieved by two methods, one is the handcrafted extraction of features (Xianghua, et al., 2007), and the other is by using convolution neural networks (Napoletano, et al.).
Once the features have been extracted then various machine learning algorithms can be applied to generate the feature distribution of the given images. Feature distribution of both the normal image and the test image are calculated and if the difference is more than the specified threshold then the test image is labeled as abnormal.
For detecting the location of an anomaly in the image the test image is divided into multiple sub-images of smaller size and then the method of feature distribution is applied to smaller images. This method puts forward two problems. One is the demand computational power is more since the number of images has increased and the other is that the model may not detect anomalies in sub-images that may have been detected in a whole image.
Supervised vs unsupervised learning:
For anomaly detection, unsupervised learning is preferred since it provides more robustness to the system when dealing with real-world applications. For supervised learning images with anomalies are difficult to collect and are sometimes not enough to train a model because anomalies can be in different shapes, sizes, and colors.
Conclusion
Anomaly detection in computer vision is a rapidly evolving field that plays a critical role in real-world applications like medical imaging, industrial inspection, and surveillance. Whether through image-level anomaly detection or pixel-level techniques, modern approaches such as autoencoders, GANs, self-supervised learning, and feature modeling are pushing the boundaries of accuracy and efficiency.
While supervised methods have their advantages, unsupervised learning continues to be the preferred choice for scalable and robust anomaly detection solutions. Companies looking to implement these advanced solutions often choose to hire Data Consulting and AI Services Company with expertise in AI and computer vision to ensure precision, reliability, and faster deployment.
As deep learning and AI technologies advance, the ability to detect anomalies with higher precision and lower false positives will only improve—paving the way for smarter, more secure visual systems.

























