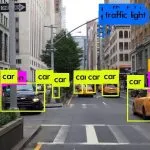
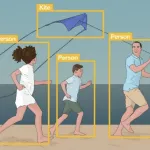
Computer Vision in 2021
The core concept of any Computer Vision-based system lies in perceiving its environment in return taking the actions based on its perceived knowledge. CV is its whole concern. The model is constructed for the world by applying CV on images and videos to generate real-world applications.
Computer Vision: an evolution bringing the superhuman achievements
Recent Computer Vision, Deep learning advancements, and applications have surpassed the human ability of image classification and object detection. The dramatic evolution in the availability of data and computational power has enabled superhuman achievements.
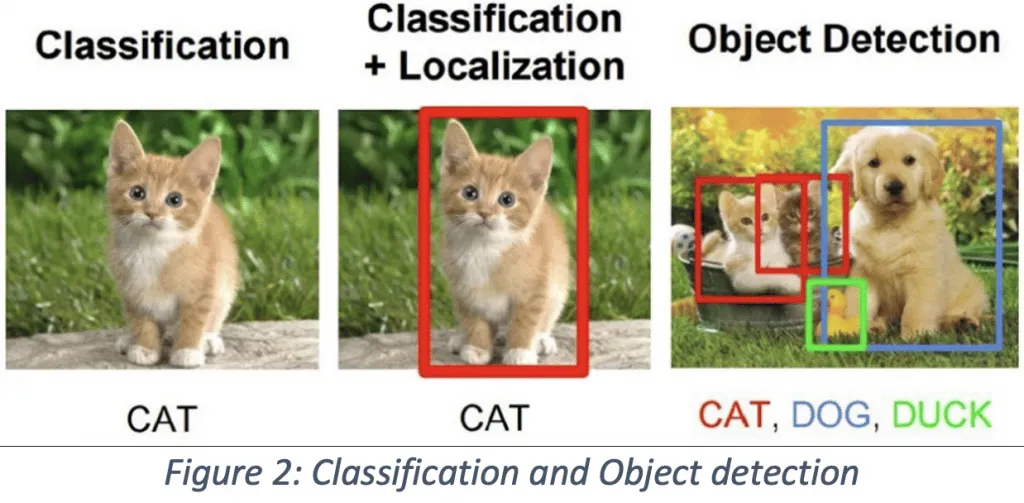
Complex Algorithms for image and video classification, object detection, and image captioning, have become simple using computer vision. Image classification is one of the most basic applications for convolutional neural networks (CNN).
Images are taken as a single object, and the main task of image classification is to label each image. Several object detection systems have been developed, including CNN, R-CNN, Faster R-CNN, single-shot detection (SSD).
Another detection system has been recently developed named You Only Look Once (YOLO), which is a one-time CNN to predict the positioning of the frame and classification of multiple candidates in that frame. It is used to achieve end-to-end detection of the target object. Regression solution is used in YOLO to solve the problem of object detection. The bounding box is drawn around the detected object with its predicted category. The process ends with putting the obtained output to the position and specific class.
YOLO
YOLO is a single-stage detection; it handles object detection and classification at a single step passing the network. YOLO is also considered more performant in terms of accuracy and speed handling. The family of YOLO models has continued to evolve since its initial release in 2016.
YOLOv1
YOLOv1, also known simply as YOLO, is a one-stage or unified network, is the first version of this novel approach. It is based on the concepts of object detection in real-time instead of object detection like previous techniques in which a window slide is used to feed the outputs into the classifier and generate the bounding boxes.
YOLOv2
YOLOv2 is an improved version of YOLO. It also runs on different image sizes, but its uniqueness lies in introducing several new methods of training for classification and object detection, including multi-level training with higher image resolution, batch normalization, and final image output prediction with higher spatial using default bounding boxes.
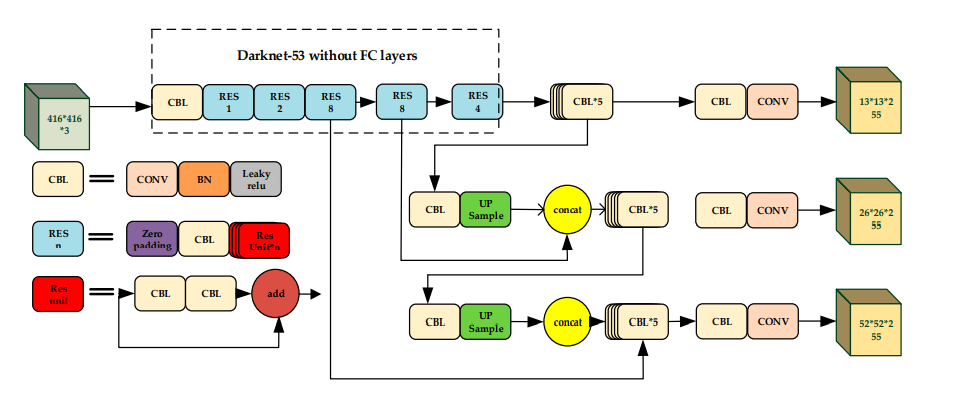
YOLOv3
YOLOv3 is the third version with a different approach from the last two versions. It develops a 53-layered deeper network known as Darknet-53, which combines the state of art techniques, including skip connections, up-sampling, and residual block with the network. The techniques of skip connections and residual blocks are very favorable for ResNet and relatable approaches. 53 more layers are added onto it, providing the 106-layered fully convolution network underlying architecture.
YOLOv4
YOLOv4 is the advanced iteration of YOLOv3 for object tracking. The purpose of object detection is to recognize where and what. The operating speed of YOLOv4 is the fastest, which directly influences the parallel computations and optimization in detection. YOLOv4 captures the image completely during the testing and training phase, so its use in encoding contextual information is of greater importance. YOLOv4 framework works in a series of steps. The first step of the algorithm is taking the input image. The next step is dividing the image into grid form, which can be any m * n number of grids. Then localization and classification are applied to each grid.
In the end, YOLOv4 enables the prediction of bounding boxes according to the class probability of objects. Each bounding box can be predicted using four parameters, including width, height, center coordinates of the bounding box, and value cis, which corresponds to the specific class of object.
ResNet as a feature extractor
For getting higher values for precision, YOLOv4 uses a more complex and deeper network via Dense Block. The backbone of YOLOv4, which is used for feature extraction, itself uses CSPDarknet-53. The CSPDarknet-53 uses the CSP connections alongside Darknet-53, gained from the earlier version of YOLO.
Four apparent blocks for YOLOv4 are backbone, neck, dense prediction, and sparse prediction (mainly used in faster R-CNN). The backbone used in YOLOv4 is CSP which is abbreviated for cross-stage partial connections. The neck block is used for adding layers after feature extraction and before the dense prediction block.
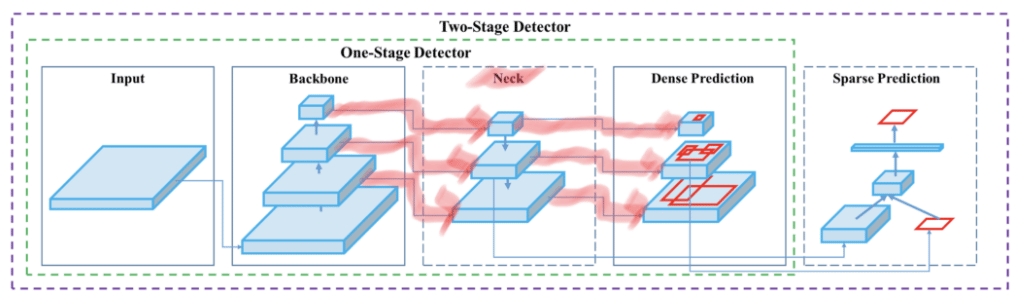
Although YOLO has proved its object detection capability in multi-scale and anchor boxes, its accuracy in detecting position is not highly effective in the case of small objects. The best way to the improvement of model accuracy is by designing the network as deep as possible. But it has one subsequent gradient disappearance, which can be solved using ResNet, which solves the problem of gradient disappearance and improves the accuracy of the model. Hence, ResNet is added for feature extraction.
Hybrid network of YOLO and ResNet
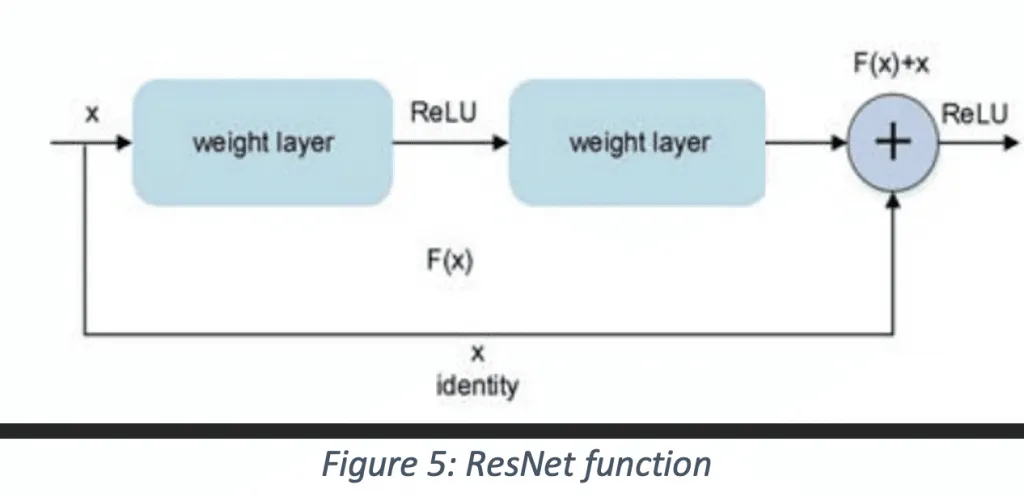
The hybrid network based on YOLO and ResNet extracts the features jointly. In the case of ResNet, a branch is added that directly connects the input and output of the entire module. The convolved output and input are summed together for getting the final output. One more defending factor for ResNet is that it does not add additional calculations and parameters to the network. Still, it can highly improve the training effect and training speed of the model.
The output of the two models with features extracted is averaged to reduce the dimensions. At the final step, the feature layer after upsampling and middle layers of feature extraction are spliced together to generate a more distinct map and prediction on three scales.
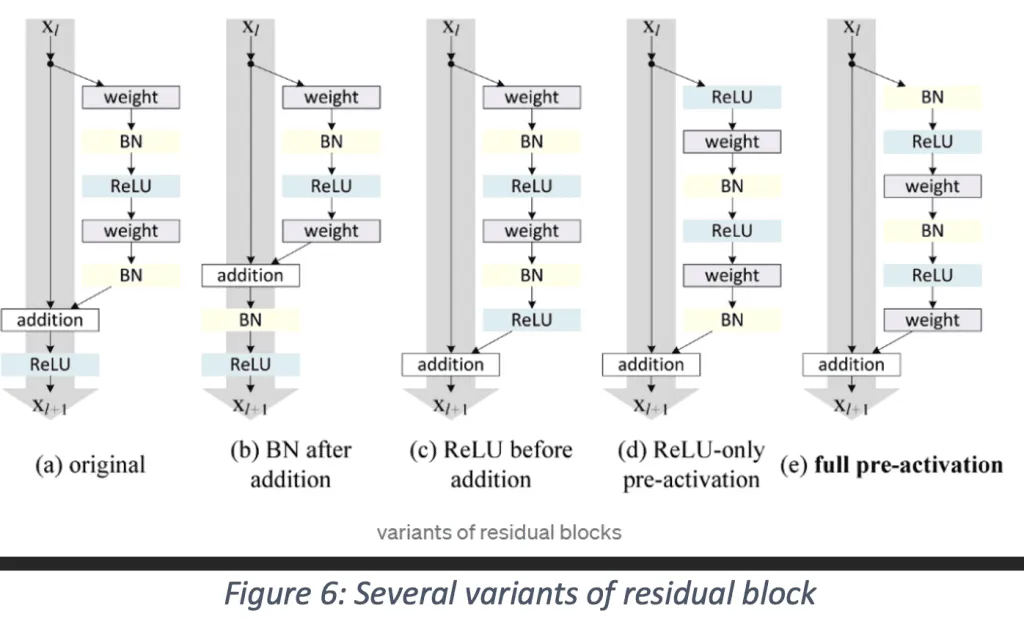
Different variants of ResNet have been utilized from original to full pre-activation in which the gradients can flow unimpededly through the shortcut connections to any of the earlier layers.
The applications of computer vision and deep learning are growing at a great pace on the business side. Algoscale provides you consultation regarding the incredible amount of visual data along with the noticeable innovations in convolutional neural networks. Algoscale makes it easy for you to envision several applications, including business and the industrial side. Development in AI-based applications provides you a competitive advantage, and Algoscale delivers data combinations and analytics assisting this technological development.
Algoscale has successfully built its real-time object detection with YOLO. Which classifies vehicle type, license plate number, and vehicle make, and finally stores the data in the database. Inference pipeline is developed on the toll plaza, which has multiple cameras running on it. The edge server is used to install the entire system, and the model categorizes the vehicles with 95% accuracy.
You can check the performance of our algorithm here on YouTube.