Hadoop and Spark are two popular big data frameworks maintained by the same identity, Apache Software Foundation. Both are open-source software and are ideal for high-level data processing.
Hadoop is an older one of both frameworks and had once been the most preferred choice for big data processing. Though the arrival of Spark has affected the popularity of Hadoop, Hadoop or Spark, which is better, has become a common question among many businesses.
If the same question is also bothering your mind, this article is worth your interest. We will discuss Hadoop vs Spark by unwrapping various aspects of both platforms. With this information, you can better pick the framework for your next data processing requirement.
What is Apache Hadoop?
As stated above, Apache Hadoop is based on open-source technology, enabling users to handle huge data sets flawlessly with the help of nodes to fix complex and intricate data issues. With exceptional competence in storing as well as processing all types of data (structured, unstructured, and semi-structured), it becomes a cost-effective and scalable solution.
What is Apache Spark?
Like Hadoop, Apache Spark comes from the same open-source family with some remarkable qualities. With its great big data management and processing capabilities, it has become one of the best big data frameworks globally. There are multiple ways to deploy Apache Spark, offering native bindings to Python, Scala, Java, etc. programming languages. It also works well with Machine Learning, SQL, graph processing, and Streaming data.
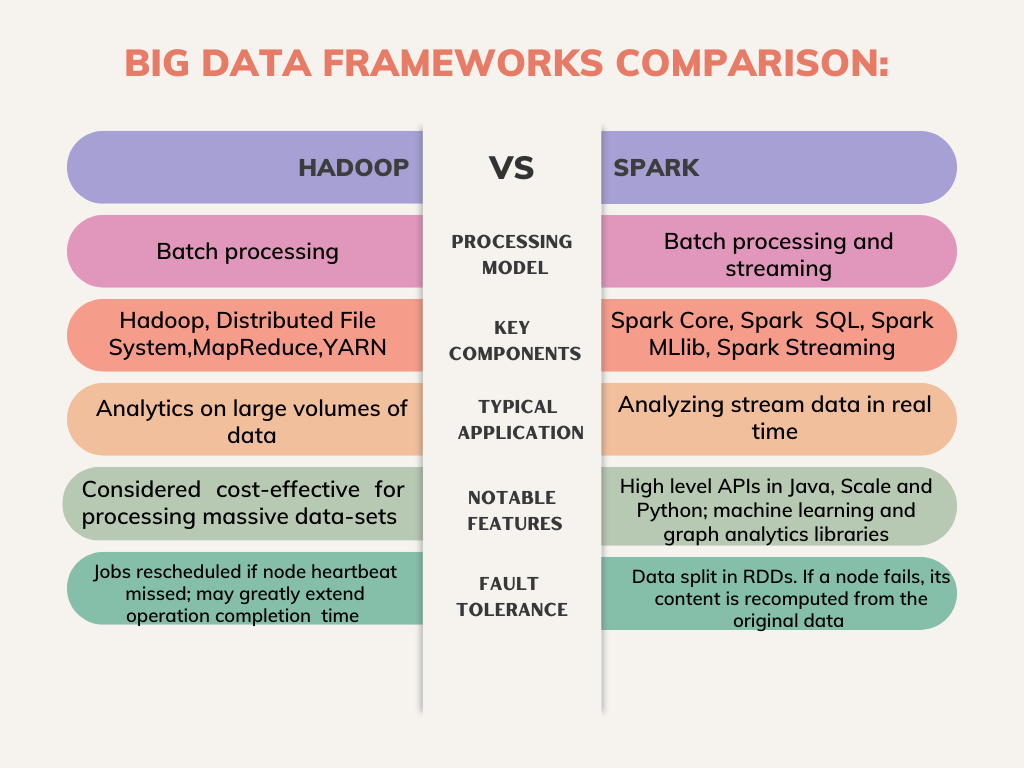
Hadoop vs Spark: Big Data Frameworks Comparison –

Apache Hadoop and Spark belong to the same ethnicity. Or we could call Spark an enhanced version of Hadoop with MapReduce. In addition, there are some significant differences between these two Big Data frameworks – Hadoop vs Spark, which we are discussing here –
- Open Source – As both the frameworks are open-source and support scalable, reliable distributed data computing, we can clearly acknowledge a tie between Hadoop and Spark on this parameter.
- Fault-tolerance quality – Again, both platforms demonstrate equal strength on system failure or fault tolerance. Hadoop performs well even if a cluster node fails. With heartbeat messages and data replication, they achieve fault tolerance. Regarding Spark, RDDs are the main ingredient to make it fault tolerant.
- Performance and speed analysis – Performance-wise, we must acknowledge that Spark is the clear winner as it is faster with RAM usage rather than depending upon disks for reading/writing transitional data. On the contrary, Hadoop uses multiple sources to save data and processes through MapReduce in batches.
- Hadoop vs Spark – Processing analysis – Both platforms perform exceptionally in specific conditions in the data processing. Hadoop is the perfect framework for processing linear data and batch data. However, Spark is perfect for live unstructured data streams and real-time data processing. Both frameworks depend on distributed eco-system for data processing.
- Equal at data integration capability – Data fetched from various business systems is hardly well-organized and clean, which is why integration for analysis or reporting becomes difficult. The ETL (Extract, Transform and Load) processes are used to make the data standardized.
With Hadoop and Spark both platforms, the time and cost invested in the ETL process get reduced.
- Costing difference – For data processing, Hadoop depends on any disk storage type that keeps the cost lower. On the other side, Spark depends on recollected computations to support real-time processing of data, for which it utilizes RAM in high amounts for nodes’ spin-up. Ultimately, the whole process increases the cost of this framework.
- Security-based difference – With the provisions like authentication through a shared event or secret logging, Spark features good security. Hadoop is based on multiple access control and authentication methods. In a nutshell, Hadoop offers better security, and by integrating Spark with Hadoop, the security level can be improved.
- Scalability – Through Hadoop Distributed File System, Hadoop scales up to manage the demand of growing data volume. Spark is based on HDFS to process a large amount of data.
- Hadoop Vs Spark at Machine Learning – For Machine Learning, Spark is a definite winner due to MLIib, which lies on in-memory iterative computations. In addition, it also features tools that facilitate classification, pipeline construction, evaluation, persistence, and regression.
In addition, let’s check out some use cases to find out big data frameworks comparison – Hadoop or Spark: which is better –
Apache Hadoop is a good big data framework choice in the following cases –
- Processing data sets where the size of data extends existing memory.
- Batch processing is required for tasks that dump read/writer functions of the disk.
- Archive and historical data analysis
- To complete tasks that are not time-bounded.
- Having a limited budget for building infrastructure for data analysis
After Hadoop, let’s talk about various cases where Apache Spark is an ideal choice for big data processing.
- Working with multiple operations simultaneously with iterative algorithms.
- For all machine learning-based applications
- Graph-parallel data processing for the model data
- Receiving quick results through in-memory data computations.
- Real-time stream data are analyzed.
Final takeaway – Big data frameworks comparison: Hadoop Vs Spark – which one is better:
After comparing both frameworks, we can conclude that both Hadoop and Spark have certain qualities which users for different scenarios prefer.
As Apache Spark came later to Apache Hadoop, it was meant to overcome the shortcomings of the former. So, Spark is better and faster in performance, but Hadoop has its pluses, making it a good big data framework. In a nutshell, Hadoop and Spark are two key frameworks in big data analysis, and giant players across the globe love both to streamline user experiences.
Conclusion
Hadoop and Spark have already secured a good place in the Big Data marketplace. Companies rely on the capabilities of these frameworks.
If you are looking for trusted Big Data Engineering companies that have done some exceptional work with these leading frameworks, then Algoscale is a place worth your consideration.
Being an expert in Machine Learning and Big data engineering technology, we’ve done amazing work, which you can see here. Our successful big data engineering projects speak for our expertise in this domain.