Technology has been advancing at an exponential rate and so is the computational power of our systems. One field that has benefited from this boost is the field of computer vision development. A lot of computational power is required to train object detection models to achieve high mean average precision and recall for a given model. In this blog, we will look at how computer vision development in object detection works and also discuss image recognition and image segmentation.
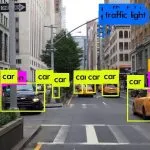
Object Detection
Image Recognition
Image recognition is another area of computer vision in which the task of the model is


Steps to perform image recognition
- Dataset acquisition.
- Dataset pre-processing
- Model configuration
- Model training
- Model evaluation
Image Segmentation
Conventional object detection involves generating a bounding box around the object in each image or a video but in image segmentation, the classification and detection are not performed using rectangular bounding boxes, but it is done more precisely on a pixel level. Different classes are marked as a class according to their shapes thus giving us the information about a certain object’s shape which is not achievable in generic object detection.
Image segmentation is important where the margin of error is minuscule such as in health care industry in which finding out the severity of the cancer is determined by the shape of cancerous cells or in the Autonomous vehicle industry where the exact position of objects in the surrounding environment of the vehicle is necessary.
Image segmentation is further divided into two categories, one is semantic segmentation, and the other is instance segmentation.
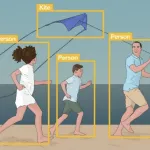
Semantic segmentation detects objects in an image and groups them based on the predefined labels. In the example below the picture on the left side is of semantic segmentation where every person is labeled in a single group.
Instance Segmentation is more robust than semantic segmentation. In this object of a single class is further categorized as can be seen in the right image. This process of labeling is computationally expensive, but it gives an edge when analyzing videos or images for computer vision-related tasks.

Conclusion

Algoscale finds the best solution for you, whether you need object tracking and detection, real-time emotion detection, surveillance system, face recognition implementation, or invoice segmentation and OCR data extraction. With our vast expertise in computer vision development services, we assist your business in improving your customer experience and automating business processes and thus, acquire relevant insights to make better business decisions. Our team of professionals can help you choose the right platform for computer vision development, develop apps, integrate the camera, and improve the efficiency of your processes by interfacing with other systems.