Artificial Intelligence (AI) has swayed how most of the people around us engage in routine activities by assessing and designing advanced and recently emerged hi-tech applications and gadgets, called “Intelligent agents”. These agents have a great potential to perform their assigned tasks intelligently without any human interference. GO-BOTs are one of these advancements. GO-Bots are AI-programmed, “Human-computer interaction (HCI)” models.
What is a Goal-Oriented Chatbot (GO-Bot)?
A “goal-oriented chatbot (GO BOT)” provides solutions to resolve some of the specific problems and challenges that the end-user faces. These Go-Bots assist in booking a ticket, finding a reservation, and more.
Since this article is more about the training of the GO-Bot, there exist two ways to train them.
- One of the training methods is through “Supervised Learning” along with an encoder-decoder which maps the user dialogue directly to the responses.
- The second method of training the GO-BOTS is through “reinforcement learning” in which the chatbot is trained via “trial-and-error conversations” with either of the two users i.e., the rule-based simulator or the actual user.
Training of GO BOTs using “Deep Reinforcement Learning (DRL)” is considered to be an innovative research field having a variety of practical applications.
GO-BOT Dialogue System Flow
The GOT-BOT dialogue system via “Deep Reinforcement Learning (DRL)” has been split into three major parts [4]:
- “Dialogue Manager (DM)”
- “Natural Language Understanding Unit (NLU)” and also
- “Natural Language Generator unit (NLG)”
In addition to the above mentioned, the DM unit is segmented into further two systems known as “Digital State Tacker (DST)” or the “State Tracker” and the “Agent Policy”, and it is represented with the help of a neural network in most of the cases.
Furthermore, the dialogue system flow comprises the user having the user goal. Here, the user goal shows the desired wish of the user to be fulfilled from the conversation. In the diagram below, the desired wish that has been acquired from the conversation is to reserve a table in a restaurant.
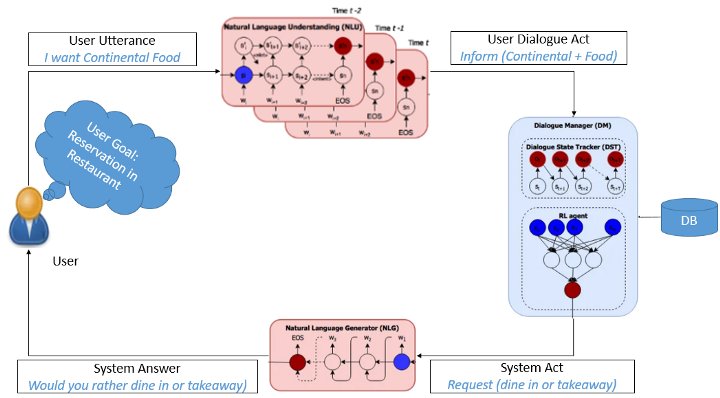
Figure 1. System Dialogue Flow
In the diagram above, it can be seen that the user or a client expresses his/her desire to be completed which is processed with the help of the NLU Unit into the semantic frames. Semantic frames are considered to be the lower-level processing or the representation of the Natural language expression that the agent processes. In the next step, the DST converts or transforms the “user dialogue act”, which is also considered to be the semantic frame, along with the history of an existing ongoing conversation to that of the state representation which is utilized by the policy of the agent. After that, the current state is given as an input to the neural network or the policy of the agent which results in the action in semantic frame form.
In this case, the database (DB) can also be probed or demanded in order to further add the information to that of the action of the agent like demanding the info about movie tickets or booking a table in a restaurant.
After gaining the information from the database, the agent action (also considered to be the system action in this case) is dealt with by the NLG element/ unit that transforms the info into the natural language so that the user can easily comprehend and understand what he has asked for.
Rule base Simulator (User Simulator)
The user simulator is considered to be the “deterministic rule-based simulator” that endeavors to model itself to the real or actual user. In this scenario, it is said to be based on the model of user agenda where it utilizes the internal state representing the constrictions as well as the requirements of the user simulator.
Through this internal state, the track of the recent and ongoing conversation along with the other basic requirement to complete the user goal is kept. The user goal is randomly selected from all of the available lists of user goals in which the goal is comprised of a complete group of limitations as well as other information which controls and leads the user simulator actions since it tries to fulfill the existing user goal. While tracking the user goal of the current conversation, the “error model controller (EMC)” is utilized to put a few errors within the action of the user simulator at the semantic frame level that is used to enhance the training outcome.
Action Framework
It is highly significant to comprehend and understand the framework of action while training GO-BOT. Here, the user simulator, as well as the agent, are considered as input and output action as semantic frames, if the NL language is ignored. It must be noted that action is comprised of the intent, inform as well as request slots. Slots are referred to as the keys, value pair that intends to the requestor single inform.
For instance, in a framework of movie ticket data, {‘tonight’, ‘theatre’; ‘start time’} and {‘theatre’, ‘start time’} are taken as the slots.
Agent Training
Training of the whole system is comprised of four significant parts:
- The agent
- DST
- User simulator
- EMC (error Infuser)
Different stages that are followed for completing one loop of the system are described below:
- Initially, the current state is given as the input to the action method of the agent.
- In the second step, the action of the agent is sent to the state tracker (ST). Using this, ST updates its conversation history and also updates the agent acts through “database query information”.
- In the third step, the updated action of the agent is given as the input to the step method of the user. Here, the user simulator builds its own “rule-based response” and as results provide the reward as well as success information.
- After that, the action of the user is imbued by the error using EMC.
- The error-infused user action is transferred as input to ST in order to take the user action, where the information is saved in the history.
- In the final step, the upcoming state is resulted from the “get state” of ST, thus completing the existing system flow which is then added to that of the agent’s memory.
How Algoscale can assist in training your Go-Bot?
We hope that this article has been of significant help to you in understanding the training of GO BOTS. During the pandemic, almost all businesses have allowed their employees to work remotely. However, there are some circumstances where customers require 24/7 assistance. It becomes difficult for the employee to assist their clients and customer for such a long period. Therefore, many businesses have adopted GO BOTs to tackle these kinds of situations by providing AI-driven solutions to the customer.
Algoscale provides its services by connecting to businesses in this domain. If any business is looking for help regarding the training of GO Bots, then Algoscale is here to help you. We provide our customers with the best possible outcome concerning GO Bot training.