Apache Spark is an open-source, distributed processing platform for big data workloads. It offers two key data abstraction APIs for efficient data processing and analytics: Resilient Distributed Datasets (RDD) and DataFrames.
While both APIs serve similar purposes and can produce the same output from a given input, they differ significantly in data handling, performance, support, and user experience. These differences allow users to choose the API that best fits their needs when working with Spark.
In this article, we’ll explore the features, specifications, and use cases of both RDDs and DataFrames. By the end, you’ll have a clear understanding of which API is better suited for grouping and processing your data.
Introduction to Apache Spark RDD
RDD is an immutable distributed collection of data objects partitioned across the nodes of a cluster in Apache Spark.
It enables a developer to process computations on large clusters inside the memory in a resilient manner, increasing the efficiency of every task. RDD is well known for its fault-tolerance. Because these records are immutable, they can also be recovered if a partition is lost.
When to Use RDDs?
Spark RDDs are beneficial in the following scenarios:
- When dealing with unstructured data, such as text or media streams, RDDs offer better performance.
- For low-level transformations, RDDs help streamline and accelerate data manipulation, especially when working close to the data source.
- If a schema is not critical, RDDs don’t enforce one. However, they can still use a schema to access specific data based on columns when necessary.
Introduction to Apache Spark DataFrames
Compared to RDD, data in the DataFrame is arranged into named columns, i.e. each column has a name and associated type.
It is a fixed distributed data collection that enables Spark developers to implement a structure on distributed data. This way, it allows abstraction at a higher level.
When to Use Dataframes
Spark DataFrames are ideal in the following scenarios:
- When working with structured or semi-structured data, DataFrames provide schema support and high-level abstractions.
- If you need to store one-dimensional or multidimensional data in a tabular format, DataFrames are well-suited.
- For high-level data processing, DataFrames offer convenient, built-in functions that simplify complex operations.
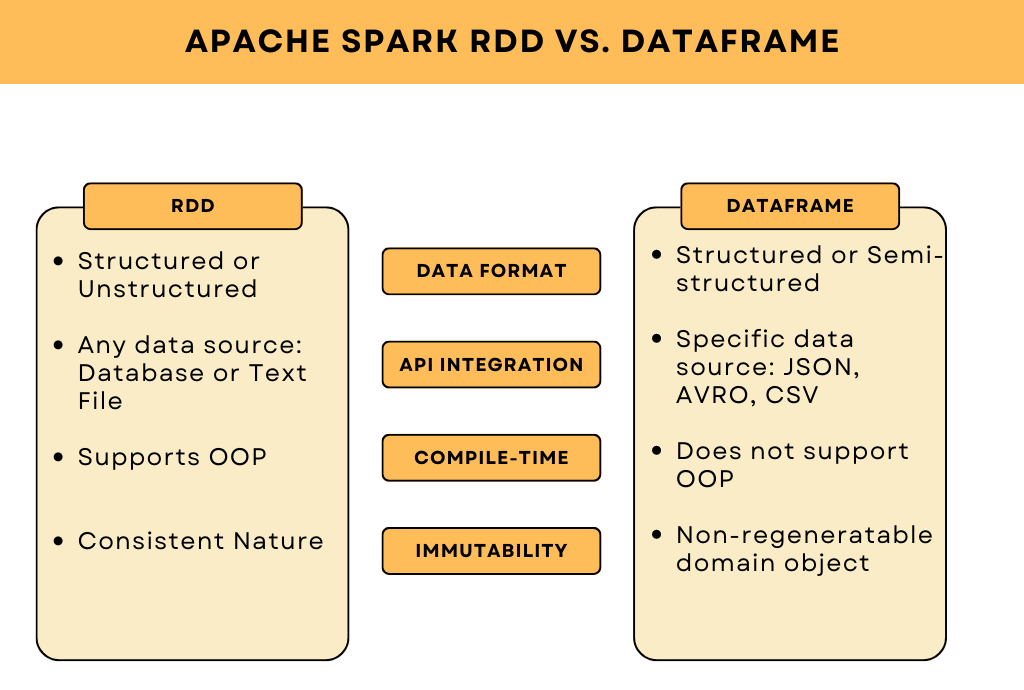
Difference Between RDD and Dataframes
In Spark development, RDD refers to the distributed data elements collection across various nodes in the cluster. It is a set of Scala or Java objects to represent data.
Spark DataFrame, on the other hand, refers to the distributed collection of organized data in named columns. It is like a relational database but with better optimization techniques.
Now let’s examine the key differences between the two Spark APIs. This will help you understand the two more comprehensively and choose the right strategy for your business data processing.
1. Format of Data
Spark RDDs can efficiently process structured and unstructured data but don’t automatically provide a schema, leaving users to define it themselves.
On the other hand, DataFrames are designed to handle structured and semi-structured data, much like a relational database, and come with built-in schema management for easier data organization.
2. Integration with Data Sources API
RDDs offer enhanced flexibility when working with various data types, from text files to extensive databases. However, they lack direct integration with external data sources. This means you need to manually write the code to load data from external sources such as Hadoop or local files, making the process more complex and time-consuming.
On the other hand, DataFrames have built-in APIs to easily integrate with a wide range of external data sources, such as JSON, Hive, and CSV, among others. This automatic schema inference and easier data manipulation make interacting with external data sources more efficient and user-friendly.
3. Compile-Time Type Safety
RDDs support compile-time type safety. This means the data is carefully checked at compile time and errors are flagged early in the development process, ensuring that operations on RDDs are type-safe.
DataFrames, on the other hand, do not support compile-time type safety. The data is checked only during runtime. While this offers more flexibility in handling structured and semi-structured data, it may lead to errors being caught only during execution, which makes the debugging process more difficult.
4. Immutability
RDD’s nature is immutable. It means that nothing is changeable in RDD but it can be created through various transformations. This way, the nature of all the calculations is consistent.
For DataFrame, a domain object cannot be regenerated after transformation. Thus, if one test DataFrame is generated, the original RDD cannot be recovered again from the test class.
Use Cases of RDD
RDD has the following use cases:
- When working with unstructured data as RDDs can originate from any data source.
- If you need immediate calculations.
- If your project is written in Java, Scala, R, or Python.
- When you don’t want to specify a schema.
- For both high-level abstractions and low-level transformations.
Use Cases of Dataframe
Spark Dataframe has the following use cases:
- When handling data from specific sources like JSON, MySQL, CSV, etc.
- If you want calculations to be performed immediately after an action is triggered.
- If your project is based on Java, Scala, R, or Python.
- When you need to specify and manage a schema.
- For working with structured or semi-structured data with high-level abstractions.
| Features | RDD | Dataframe |
| Version | Spark 1.0 | Spark 1.3 |
| Representation of data | Distributed data elements | Data elements are organized in columns |
| Formats of data | Structured and unstructured | Structured and semi-structured |
| Sources of data | Various | Various |
| Compile-time type safety | Available | Unavailable |
| Optimization | No built-in engine for optimization | Catalyst optimizer for optimization |
| Serialization | Use Java serialization | Serialization occurs in memory |
| Lazy Evaluation | Yes | Yes |
RDD vs Dataframe: Which One Should You Choose?
As discussed, Apache Spark RDD provides low-level transformations and greater control, while DataFrames offer high-level, domain-specific operations that run efficiently and optimize space usage.
If your team has Spark developers familiar with Java, Scala, R, or Python, the choice between RDD and DataFrame depends on your project’s needs. For instance, if you’re dealing with distributed data elements, RDDs may be a better fit, whereas for structured data, DataFrames are more appropriate.
How can Algoscale Help
We hope that this article has clarified the difference between RDD and DataFrame. Each technology has its advantages and limitations based on the scope and specifications of the project being developed. Both can be integrated with third-party APIs, offering flexibility for various use cases.
At Algoscale, we work with a brilliant team of Spark developers who can help you determine the best API based on your project’s requirements and complexity. We provide tailored solutions to ensure optimal performance and efficiency.
If you’re looking to build a highly efficient system but don’t want to hire a full-time Spark developer, we’re here to assist you every step of the way. Get in touch with us today!